Cyberbezpieczeństwo łańcucha dostaw zgodnie z regulacjami NIS 2 i DORA
DLACZEGO BEZPIECZEŃSTWO ŁAŃCUCHA DOSTAW JEST TAKIE WAŻNE?
W dzisiejszej połączonej gospodarce nasz biznes jest tak bezpieczny, jak najsłabsze ogniwo w naszym cyber łańcuchu dostaw. Jednorazowe ankiety i audyty dostawców to już przeszłość. To tak, jakby sprawdzać prognozę pogody raz w roku. W dobie regulacji takich jak DORA i NIS 2, które kładą ogromny nacisk na zarządzanie ryzykiem stron trzecich, podejście reaktywne to prosta droga do katastrofy finansowej lub reputacyjnej. Dlatego, proaktywne zarządzanie bezpieczeństwem łańcucha dostaw poprzez nowoczesną platformę softwarową jest kluczowym elementem w uzyskaniu zgodności z wymaganiami regulacyjnymi i daje wiele dodatkowych możliwości poprawiających naszą pozycję cyberbezpieczeństwa.
JAKIE SĄ KLUCZOWE FUNKCJE PLATFORMY DO ZARZĄDZANIA RYZYKIEM STRON TRZECICH?
Nowoczesna platforma do zarządzania ryzkiem stron trzecich oferuje m.in. możliwości automatycznego identyfikowania naszych dostawców, analizuje związane z nimi cyber zagrożenia, wykrywa podatności, obserwuje i analizuje zdarzenia związane z cyberbezpieczeństwem w czasie rzeczywistym, ocenia i priorytetyzuje ryzyka własne organizacji i ekosystemu podmiotów grupy kapitałowej oraz u zewnętrznych dostawców w łańcuchu usług cyfrowych. Analityka platformy wspierana jest przez sztuczną inteligencję i bazę wiedzy.
Ponadto, platforma umożliwia w zestandaryzowany sposób odtworzenie łańcucha powiązań, analizę ryzyka cybernetycznego i określenie liczbowego Cyber Ratingu, który podobnie jak w branży finansowej, daje szybko ocenę jakości zarządzania cyberbezpieczeństwem grupy i jej łańcucha dostawców. Coraz częściej miara taka jest już wykorzystywana przez liderów branży finansowej i największe firmy.
Dodatkowo, Cyber Rating można wykorzystać do porównania swojej organizacji lub dostawców z organizacjami z tego samego sektora, aby określić mocne strony swojej polityki bezpieczeństwa i na których ryzykach należy skupić się w pierwszej kolejności. Pozwala to w prosty sposób określić priorytety niezbędnych usprawnień i przekazać je kierownictwu w celu poprawy swojej pozycji cyberbezpieczeństwa i zgodności z przepisami.
WYMAGANIA REGULACYJNE
NIS 2, Dyrektywa Parlamentu Europejskiego i Rady (UE) 2022/2555:
Art. 21 ust. 2 pkt. d:
- bezpieczeństwo łańcucha dostaw, w tym aspekty związane z bezpieczeństwem dotyczące stosunków między każdym podmiotem a jego bezpośrednimi dostawcami lub usługodawcami;
KSC, Projekt o zmianie ustawy o Krajowym Systemie Cyberbezpieczeństwa (NIS 2 PL):
Art. 8.1 e:
- podmiot kluczowy lub podmiot ważny wdraża system zarządzania bezpieczeństwem informacji w systemie informacyjnym wykorzystywanym w procesach wpływających na świadczenie usługi przez ten podmiot, zapewniający …. e) bezpieczeństwo i ciągłość łańcucha dostaw produktów ICT, usług ICT i procesów ICT, od których zależy świadczenie usługi, z uwzględnieniem związków pomiędzy bezpośrednim dostawcą sprzętu lub oprogramowania a podmiotem kluczowym lub podmiotem ważnym;
DORA, Rozporządzenie Parlamentu Europejskiego i Rady (UE) 2022/2554 wzmocnienie odporność operacyjną instytucji sektorów finansowych (banki, towarzystwa ubezpieczeniowe, firmy inwestycyjne i inne podmioty finansowe):
Art. 8.1 e:
- środków na rzecz należytego zarządzania ryzykiem ze strony zewnętrznych dostawców usług ICT…. wymogi w odniesieniu do ustaleń umownych zawartych między zewnętrznymi dostawcami usług ICT a podmiotami finansowymi;
WYZWANIA ROZWIĄZYWANE PRZEZ PLATFORMĘ. DOSTAWCA USŁUG CYFROWYCH – CZYLI KTO?
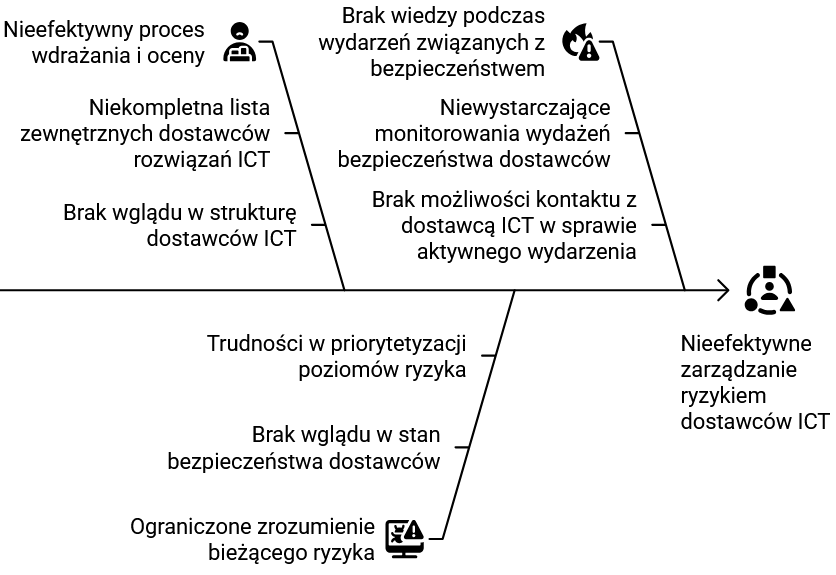
Jakie są przykładowe wyzwania związane ze stronami trzecimi, skutkujące nieefektywnym zarządzaniem ryzykiem:
- niedoskonałe procesy wdrażania zgodności i oceny obecnego stanu zarządzania cyberbezpieczeństwem,
- niekompletna lista dostawców usług cyfrowych lub brak wiedzy o ich strukturze,
- brak wiedzy o incydentach bezpieczeństwa stron trzecich i brak wglądu w ich procedury i polityki,
- brak lub słaba komunikacja z odpowiednimi zespołami cyberbezpieczeństwa,
- trudności w priorytetyzacji poziomów ryzyka,
- trudność identyfikacji dostawców ICT organizacji (serwisów chmurowych, oprogramowania na zasobach…).
Przykładowo dla branży usług finansowych kluczowe mogą być następujące grupy dostawców:
- infrastruktura i chmura – dostawcy usług chmurowych, kolokacyjnych, Data Center, dostawcy sieci i komunikacji,
- cyberbezpieczeństwo – dostawcy rozwiązań bezpieczeństwa, dostawcy usług SOC lub MDR, dostawcy pentestów, audytorzy,
- oprogramowanie i Systemy Corowe – dostawy aplikacji corowych, ERP i CRM, dostawcy usług płatności i rozliczeniowych,
- analityka, AI oraz Big Data – dostawcy rozwiązań w zakresie analityki, Big Data, AI,
- rozwiązania do wymiany danych z organizacjami branżowymi, instytucjami nadzoru i regulatorami,
- inne usługi np. aplikacje KYC, fraud prevention etc.,
- firmy consultingowe integratorzy rozwiązań.
CIĄGŁY MONITORING
Nie da się skutecznie zarządzać bezpieczeństwem dostawców bez odpowiedniego zapewnienia mechanizmów kontroli bezpieczeństwa własnego – w nowoczesnej platformie to sprawa absolutnie priorytetowa i jest podstawą ciągłego monitorowanie dostawców usług, a w szczególności tych uznawanych za krytycznych dla naszego łańcucha dostaw.
Platforma buduje nasz rating cyberryzka (algorytm) w oparciu o 25 wektorów ryzyka poklasyfikowanych jako ryzyka systemowe, ryzyka wynikające ze zdarzań i związane z zachowaniami użytkowników. Dane uzupełnione są przez informacje o naruszeniach systemowych, zdarzeniach związanych z udostępnianiem plików i konfiguracji DNS oraz z innych źródeł. Platforma nie testuje i nie penetruje sieci wewnętrznej firmy, ale określa co, na podstawie ruchu z określonej adresacji, konfiguracji DNS i certyfikatów, może wskazywać na słabości zabezpieczeń i potencjalne zdarzenia związane z organizacją.
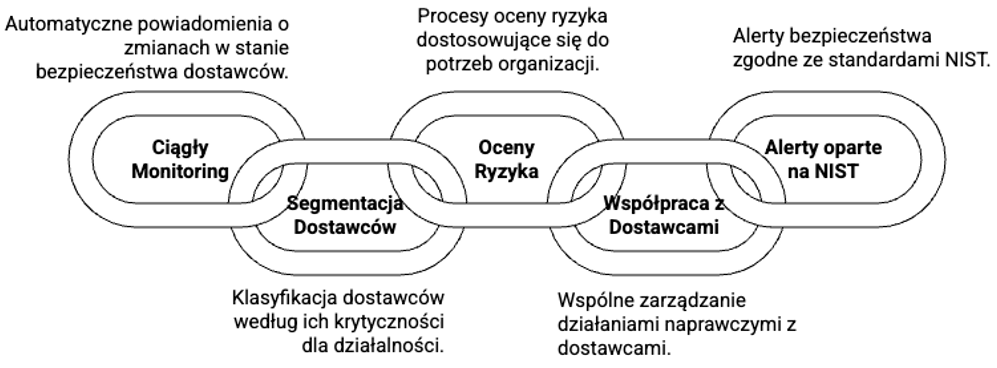
Przykładowe możliwości jakie zapewnia opisywana platforma:
- Segmentacja i klasyfikacja dostawców według poziomu krytyczności dla działalności organizacji, zgodnie z ewidencją stron trzecich,
- Skalowalne procesy oceny ryzyka dostawców, ich wdrażania i zarządzania relacjami,
- Ciągły monitoring dostawców z automatycznymi powiadomieniami o zmianach w ich stanie bezpieczeństwa, w tym zagrożeniach związanych z chmurą, uzupełniany o coroczne oceny ryzyka,
- Lepsza współpraca z dostawcami w celu wspólnego zarządzania działaniami naprawczymi,
- Alerty oparte na standardach NIST.
NAJPIERW: IDENTYFIKOWANIE DOSTAWCÓW
Nowoczesna platforma automatycznie identyfikuje portfolio dostawców powiązanych z organizacją, wykorzystując dostępne publicznie dane. Uwzględnia informacje o branży, wielkości, poziomie istotności oraz używanych technologiach. Pozwala to stale aktualizować rejestr firm, a także stanowi punkt wyjścia dla organizacji, które dopiero tworzy swoją listę dostawców zgodnie z i do celów raportowania w ramach regulacji (np. NIS 2 lub DORA). W rezultacie platforma tworzy i wizualizuje listę powiązań, a na każdym etapie można ją uzupełnić w manualny sposób.
Zbudowanie listy umożliwia szybki wgląd w wykaz dostawców oraz ich aktualne oceny (Cyber Rating) bezpieczeństwa, a także umożliwia obserwowanie trendów, zmian oceny lub zmian charakteru relacji z danym podmiotem.
Informacje o podmiotach można uzupełniać przez nadanie odpowiednich priorytetów względem ich krytyczności i wpływu na działalność operacyjną organizacji oraz wpływ na poziom ryzyka, dzieląc je na tzw.: Tier(s) (Tier1, Tier2, Tier3 … etc.). Pozwala to na definiowanie alertów z odpowiednim priorytetem oraz odpowiednie reakcje.
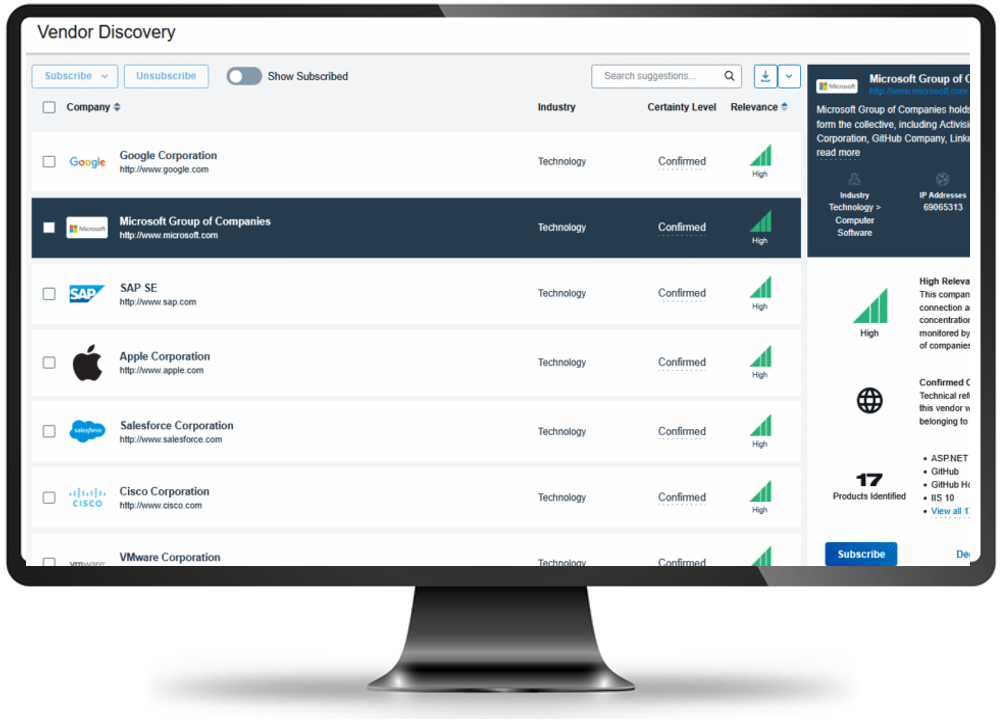
Automatyczne wykrycie łańcucha dostawców cyfrowych
PO DRUGIE: ANALIZA RYZYKA
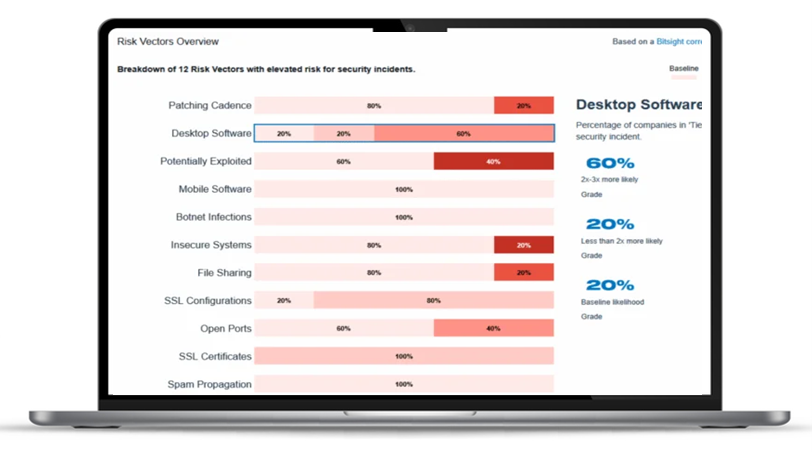
Rozkład obszarów ryzyka wybranego dostawcy
Moduł Risk Analytics pozwala zrozumieć i priorytetyzować najbardziej istotne zagrożenia w łańcuchu dostaw. Odpowiada na pytania: „Jak mogę ograniczyć całkowite ryzyko związane z moimi dostawcami?”. Na podstawie analizy danych generowana jest lista działań oraz raporty do wykorzystania przez zarząd i interesariuszy.
Dane z tego modułu pozwalają na ustalanie celów rocznych (np. obniżenie ryzyka dla wybranego segmentu dostawców) i analizę danych ułatwiającą wykrywanie wskaźników potencjalnych incydentów.
Moduł obsługuje dużą liczbę dostawców i umożliwia interaktywną eksplorację danych i filtrowanie informacji według poziomu ryzyka i rodzaju zagrożeń (np. incydenty, ransomware).
PO TRZECIE: WYKRYWANIE PODATNOŚCI I REAGOWANIE
Istotnym elementem monitorowania dostawców są możliwości wykrywanie i reagowanie na krytyczne podatności oraz zdarzenia zero-day, mogące się pojawić w oprogramowaniu i systemach dostawców. Dedykowany moduł w platformie, który umożliwia zarządzanie podatnościami w skali całego ekosystemu dostawców, automatyzuje analizę zagrożeń i dostarcza gotowe scenariusze działania.
Kluczowe informacje o najnowszych, istotnych podatnościach – takich jak zero-day vulnerabilities, mogą być też przygotowywane i dodane przez zespół profesjonalnych analityków na podstawie bieżących informacji rynkowych. Użytkownik platformy otrzymuje listę firm narażonych na dane podatności oraz szczegóły dotyczące możliwych działań naprawczych. Dzięki temu organizacje nie muszą samodzielnie śledzić wiadomości branżowych ani kontaktować się z każdym dostawcą oddzielnie – system dostarcza gotowe informacje ułatwiające ciągłą kontrole poziomu bezpieczeństwa dostawców.
PO CZWARTE: SZCZEGÓŁOWE ANALIZY DOSTAWCÓW
Wgląd w szczegóły dotyczące dostawców (Overview) daje dostęp do dodatkowych danych: aktualnych ocen bezpieczeństwa, historii zmian, ostatnich zagrożeń, ryzyk, incydentów, podatności, zasobów, etc.
Istotne składowe Cyber Ratingu (Rating Tree) definiuje mapa powiązań danego podmiotu ze spółkami zależnymi i partnerami, co na podstawie ustalonego algorytmu pozwala na zbudowanie całościowego Cyber Rating. Ta funkcjonalność może szczególnie pomóc w raportowaniu (choćby w ramach NIS 2). Z kolei Rating Tree wyjaśnia sposób kalkulacji cząstkowych ocen i pokazuje, jak dany dostawca wypada na tle konkurentów lub wskaźników branżowych i jaki ma udział w całościowej ocenie.
Ponadto, dalsze analizy (Findings) przedstawiają w szczegółowy sposób analizy podatności lub obszary poprawy zidentyfikowane w systemach dostawców w łańcuchu dostawców. Wskazania budowane są również z uwzględnieniem publicznie dostępnych danych, a platforma umożliwia priorytetyzację znalezionych problemów. W rezultacie możliwe jest skontaktowania się z dostawcą konkretnego rozwiązania lub usługi, w celu rozwiązania zgłoszonego problemu.
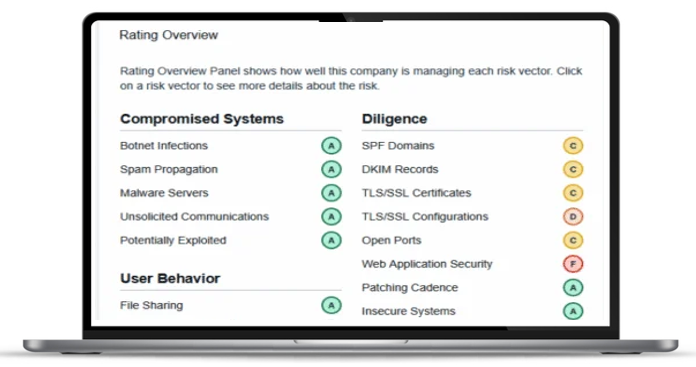
Ocena wektorów ryzyka przykładowego dostawcy
Macierz Ryzyka klasyfikuje i priorytetyzuje zgłoszone problemy bezpieczeństwa w oparciu o wagę aktywów i poważność zagrożeń, co umożliwia remediację. Pozwala zidentyfikować, które aktywa (dostawcy ICT lub własne) wymagają natychmiastowej reakcji. Możliwości monitorowania poszerzone są również o narządzie VRM (Virtual Risk Management) do wymiany ankiet z dostawcą i prowadzenia komunikacji w zakresie zidentyfikowanych ryzyk, poprawy mechanizmów technicznych lub procesów organizacyjnych.
PO PIĄTE: RAPORTOWANIE
Dedykowany moduł (Reports) umożliwia generowanie różnego rodzaju raportów, zarówno zarządczych (Executive Report), jak i szczegółowych raportów analitycznych oraz raportów w zakresie raportowanie bezpieczeństwa i ryzyka dostawców łańcucha dostaw (w zgodności z NIS 2 lub DORA). Dostępnych jest wiele profesjonalnych wzorców i szablonów, przykładowo:
- Executive Progress report aby dostać informację o postępach poprawy poziomu bezpieczeństwa lub jego obniżenia swoich dostawców ICT,
- Company preview report aby uzyskać pogląd na to, jak firma wypada na tle konkurencji na rynku,
- Portfolio Assessment report aby sprawdzić łączne ryzyko, incydenty i skuteczność zabezpieczeń dostawców ICT objętych oceną regulacyjną,
- Raporty w formie prezentacji powerpoint, Performance Summary,
- i wiele innych, w tym raporty oparte na ocenach ISO/IEC 27001 i NIST.
PO SZÓSTE: MOŻLIWOŚCI INTEGRACYJNE
Platforma oferuje liczne możliwości integracyjne. Zdefiniowany interfejs API jest potężnym narzędziem, które umożliwia programistom integrację i wymianę danych z innymi aplikacjami i systemami. Utworzono również connectory do następujących usług i aplikacji:
- Archer – wbudowany connector umożliwia przesyłanie danych o ryzyku cybernetycznym z opisywanej platformy do Archer,
- Jira – ułatwia automatyczne generowanie i przypisywanie zgłoszeń Jira bezpośrednio z platformy,
- Microsoft Azure Sentinel – rozbudowana integracja, wzmacnająca Sentinel danymi o bezpieczeństwie i źródłami ryzyka w infrastrukturze firmy, pozwalając przechodzić od świadomości do szybkiej naprawy,
- Microsoft Power BI – connector umożliwia łatwe przenoszenie danych z platformy do Microsoft Power BI w celu dalszej analizy i tworzenia pulpitu nawigacyjnego,
- OneTrust – możliwość przenieszenia danych o ocenach, dostawcach, ryzykach, incydentach, i innym do swojego spisu dostawców OneTrust,
- ServiceNow – platforma integruję się z modułami Risk Management, Security Incident Response i IT Service Management,
- Microsoft Teams, Slack – umożliwia odbieranie alertów Bitsight w wybranej platformie.
CO JESZCZE JEST WAŻNE? OCENA ZGODNOŚCI
Pewność, że nasza metoda zarządzania łańcuchem dostaw jest zgodna z regulacjami, dobrymi praktykami i frameworkami, jest ponad wszystko najbardziej istotnym elementem wyboru i wdrożenia platformy. Funkcjonalność Assessments umożliwia porównanie poziomu bezpieczeństwa dostawców z konkretnymi standardami, takimi jak CCB NIS 2 CyberFundamentals, CIS V8, ISO 27001, SIG Core, CMMC, NIST, TISAX, MVSP, CMMC.
Analizując oceny, które są wynikiem przeprowadzenia oceny w „Assessments”, organizacje mogą identyfikować i ustalać priorytety dla obszarów wysokiego ryzyka, zgodnie z naciskiem wybranej normy na zarządzanie ryzykiem. Organizacje są oceniane względem predefiniowanych pytań, np. „Czy procesy i procedury wykrywania są utrzymywane i testowane w celu zapewnienia terminowej i odpowiedniej świadomości zdarzeń anomalnych?” i otrzymują one ocenę dla każdego wektora ryzyka (np. Botnet Infections, File Sharing, Potentially Exploited).
Przykładowe frameworki dotyczące opisywanego przez nas rozwiązania:
- CCB (Centrum Cyberbezpieczeństwa Belgii) – ramy opracowane pod auspicjami rządu belgijskiego, są pierszym frameworkiem z celem zgodnośći z NIS 2. Funkcjonalność Assessments z CCB CyberFundamentals może być niezwykle pomocna dla instytucji, które muszą zapewnić zgodność z NIS 2,
- SIG Core – kompleksowy framework do oceny poziomu bezpieczeństwa dostawców zewnętrznych (trzecich) przetwarzających dane wrażliwe lub podlegających regulacjom. To szczegółowy kwestionariusz, który ma na celu dogłębne zrozumienie sposobu, w jaki dostawcy zabezpieczają informacje i spełniają wymogi zgodności,
- ISO 27001 – jest uznawany za międzynarodowy standard cyberbezpieczeństwa, służący do weryfikacji programu cyberbezpieczeństwa — wewnętrznie i w odniesieniu do podmiotów zewnętrznych. Ocena względem ISO 27001 pozwoli nam zrozumieć, jak dobrze organizacja się do nich stosuje.
Zgodność platformy z frameworkami
Jeżeli planujesz wdrożenie Zarządzania Bezpieczeństwem Łańcucha Dostawców – zapraszamy do kontaktu.
Igor i Marek
Złe praktyki, które niespodziewanie działają jako obrona przed atakami socjotechnicznymi.
Dobre i złe praktyki wypełniają nasze codzienne życie, wpływając na realne efekty i satysfakcję z wykonywanych zadań. Przez większość czasu skutecznie „gramy w tę grę” wypełniając zadania w świecie materialnym, ale w tym samym czasie nie jesteśmy w stanie zidentyfikować zasad w świecie wirtualnym.
Niesławna trójka
Poniżej znajdziesz trzy najpopularniejsze złe praktyki, które z zasady pogarszają wydajność pracy. Zaskakująco, te same praktyki działają jako rodzaj tarczy w atakach typu „-ishing”:
- Prokrastynacja – bardzo złe zarządzanie czasem, które pogarsza nasze samopoczucie i zmusza nas do pracy pod presją.
- Brak autorytetów – bardzo niskie zaufanie do osób, które przez formalną relacje i/lub zobowiązanie każą nam wykonać jakąś czynność. W tych sytuacjach czujemy się zmuszani do posłuszeństwa i pojawia się potrzeba oporu.
- Zbyt długie, nie czytam – połączone siły dwóch poprzednich punktów, powodują brak motywacji do zrozumienia szerszego kontekstu, skłaniając Cię do podjęcia decyzji nie tylko pod wpływem emocji, ale i ograniczonej wiedzy.
Zasady gry
Działanie niesławnej trójki może być wzmocnione przez zestaw efektów ubocznych takich jak stres, presja, brak czasu, brak pracy zespołowej i innych. To wzmocnienie działa do momentu, gdy te efekty uboczne tworzą stan FOMO (Fear Of Missing Out), który pod groźbą utraty kontroli nad sytuacją motywuje nas do działania, skutecznie eliminując złe praktyki.
FOMO, gdy aktywowane, staje się naszą motywacją, aby przeciwdziałać niskiej produktywności i zwiększyć efektywność w podejmowaniu decyzji poprzez:
- Zmniejszanie czasu poświęcanego na podejmowanie decyzji.
- Zmniejszanie ilości danych, niezbędnych do budowaniu kontekstu.
Te dwa czynniki to „słabe punkty w cyberbezpieczeństwie”, które kryminaliści na co dzień wykorzystują poprzez ataki typu *ishing, takie jak:
- Phihsing – używanie wiadomości email do przejęcia twojej aktywności.
- Vishing – używanie wiadomości głosowych, w celu perswadowania i manipulacji.
- Smishing – używanie SMS lub innego sposobu przesyłania wiadomości, aby nakierować lub wpłynąć na twoje decyzje.
- Quishing – oszustwa przy użyciu kodów QR,
- Someishing – oszustwa przy użyciu mediów społecznościowych.
Wszystkie powyższe ataki bardzo efektywnie wykorzystują „ludzką naturę”, w miarę jak szukamy najlepszych rezultatów.
Zasady cybergry
Zasady wydajności w cyberprzestrzeni różnią się od tych uformowanych przez nasze doświadczenie życiowe. Automatyzacja naszego umysłu może być wykorzystana przeciwko nam, więc musimy ją zużytkować dla naszego bezpieczeństwa (tak jak np. technologie AV/XDR, MFA, programy do zarządzania hasłami, NGFW/IPS/IDS i inne). Najlepsze reakcje naszego mózgu nie gwarantują najwyższej możliwej produktywności, ale mogą stanowić skuteczną obronę przed atakami socjotechnicznymi. Doskonałymi przykładami jest wyżej wymieniona niesławna trójka.
Prokrastynacja – jest użyteczna w ochronie przed zachęcaniem do automatycznej reakcji, kiedy twoje zachowania zdominowane są przez emocje. Ktoś chce żebyś działał od razu w cyberprzestrzeni? Rozłącz połączenie sugerując, że teraz nie możesz rozmawiać, przewiń do następnego posta, zrzuć powiadomienie i pozostaw do późniejszej analizy. Jest szansa, że o tym zapomnisz. A może dzięki temu zdemaskujesz oszustwo. Przestępcy przeprowadzają ataki na dwa sposoby: szeroko lub zorientowane na konkretną osobę lub grupę. Prokrastynacja może pomóc uniknąć pierwszego i wzbudzić podejrzliwość w przypadku drugiego, dzięki spowolnieniu reakcji i daniu sobie czasu na analizę sytuacji.
Brak autorytetów – Tak, dobrze słyszałeś! Kwestionuj wszystko co wysyłają Ci przez e-mail czy SMS. Pojedyncza wiadomość jest tylko sygnałem w cyberprzestrzeni. Możesz ja zignorować, a jeżeli chcesz być pewny przejdź do źródła i zweryfikuj ją (sprawdź Bank, zadzwoń na policję lub inny autorytet). Wiadomość zawiera twoje osobiste lub wrażliwe informacje? Co z tego. Dane większości ludzi są dostępne bez autoryzacji, nie ustalaj na ich podstawie autentyczności. Czy zadzwoniono do ciebie z banku? Czy ktoś zna twój numer karty kredytowej? Co z tego? Zapytaj o to, ile wydałeś przez ostatni rok na podróże – Nie wiedzą? Więc to nie jest twój bank!
Zbyt długie, nie czytam – Czy otrzymałeś wiadomość, telefon lub zapytanie, które „buduje kontekst”? Zignoruj je. Jeżeli informacja jest ważna najprawdopodobniej kontakt ponowi się. Zaplanuj czas na swoją uwagę również następnego dnia. Użyj dowolnej wymówki: wyczerpanie, przepracowanie, problemy ze zdrowiem… nie masz czasu lub siły by „nauczyć się nowego kontekstu”, więc odłóż go lub pozostaw na zawsze. Jeżeli atak nie jest wycelowany, jego koszt jest niski i prawdopodobnie nie zostanie ponowiony w najbliższym czasie. Personalizacja zwiększa koszt i zmniejsza ewentualny zysk cyberprzestępcy, nawet jeżeli użyją twoich publicznie dostępnych danych.
Najlepsze praktyki do używania złych praktyk.
Bądź czujny. Mierz swój sukces. Tak jak jest trudno zracjonalizować dobre praktyki w celu zwiększenia produktywności, tak samo trudno jest zawsze kończyć dzień w dobrym nastroju, zwłaszcza w czasie pandemii. Nie czuj się winny, jeżeli zauważysz słabą wydajność twojej pracy. Zamiast tego użyj jej, by zracjonalizować ogrom informacji jaki pochłaniasz z cyberprzestrzeni. Daj sobie czas. Jeżeli coś jest pilne, są inne metody podejmowania ważnych decyzji. Użyj robotów i technologii, by zautomatyzować proces podejmowania decyzji i poczekaj, a przynajmniej ochłoń trochę. Każdy ma swoje granice. Znaj swoje i korzystaj z nich mądrze.
Bądź bezpieczny. Dbaj o zdrowie. Bądź sobą.
Artur Marek Maciąg
Inicjatywa Kultury Bezpieczeństwa, doświadczony ekspert i pasjonat bezpieczeństwa informacji.
Pechowa Dwunastka: Gra do jednej bramki
„Gra do jednej bramki” czy bardziej dosłownie, dążenie do wspólnego celu zazwyczaj bywa trudne do osiągnięcia zarówno w ramach środowiska zawodowego jak i prywatnego. Wszędzie tam, gdzie pojawiają się choćby dwie osoby, co najmniej dwa punkty widzenia zaczynają mieć znaczenie. Dlaczego o tym wspominamy w kontekście pechowej dwunastki błędów ludzkich?
Z powodu braku współpracy, jako jednego z bardziej oczywistych czynników prowadzących do incydentu czy wypadku. Ten składnik porażki jest tak powszechny i jednocześnie tak szeroko akceptowany, że z łatwością można odnaleźć go praktycznie w każdym incydencie bezpieczeństwa. Warto jednak zwrócić uwagę na kilka sytuacji, gdzie jego obecność znacznie utrudnia powrót do stanu normalnego i najczęściej eskaluje zakres strat wynikających z incydentu.
Zacznijmy od ofiar. Przyjęło się powszechnie uważać (zapewne w wyniku próby szybkiego rozwiązania problemu), że obecnie obserwowana w mediach duża skala zjawiska kradzieży tożsamości i oszustw finansowych z jej użyciem wynika głownie z winy samych ofiar – braku ich współpracy w zakresie stosowania dobrych praktyk i uważności. Faktyczną skalę zjawiska można prześledzić w tym raporcie i choć dane wskazują na zmniejszenie zjawiska (wbrew doniesieniom medialnym) to autorzy raportu między innymi wskazują na związek pomiędzy szybką reakcją użytkowników i zastrzeżeniem dokumentu tożsamości (baza ma ponad 1.7 mln rekordów w tym roku). Mimo tego pozytywnego trendu, około 12 zdarzeń tego typu występujących każdego dnia wskazuje, że problem nadal istnieje i nie jest marginalny. Dlaczego „nie współpracujemy” jako użytkownicy z zalecanymi dobrymi praktykami? Do głównych powodów zaliczamy:
- Założenie, że błędy i wypadki nas nie dotyczą, zdarzają się wyłącznie innym
- Brak świadomości konsekwencji
- Brak wiedzy na temat dobrych praktyk
- Brak organizacji, a przez to czasu na dobre praktyki
- Zbyt dużą pewność siebie
- Poleganie na przekonaniu, że „na pewno ktoś o to dba, ja nie muszę”
- Brak wypracowanych nawyków uwzględniających dobre praktyki
Ten sam problem nazywany w środowisku służbowym „brakiem zgodności z wymogami” jest często objawem różnicy w priorytetach bądź celach pomiędzy „niezgodnym” użytkownikiem a organizacją.
Idąc dalej tym tropem, szybko odnaleźć można dalsze przykłady obecności czynnika „braku współpracy”:
- „nie mam na to czasu” – jedna z najczęściej powtarzanych fraz związanych z ochroną własnych interesów i nie dostrzeganiem wspólnego celu, występuje powszechnie w organizacjach ze złym zarządzaniem zasobami i brakiem ustalonych priorytetów zadań, pojawia się gdy personel nie jest pewny swojej pozycji i stosuje strategię „nic beze mnie” tworząc sytuacje pojedynczego punktu awarii/szyjki butelki. Pozornie ta strategia promuje współpracę z tym konkretnym pracownikiem, jednak efektywnie prowadzi do utrudnień komunikacyjnych, przestojów w realizacji zadań, presji na wszystkich uczestników procesu. Przeciwdziałanie temu efektowi wymaga rozwijania kompetencji Poznaj, Prywatność oraz Odzyskaj. Organizacyjnie należy upewnić się, że wspólny cel jest wartością znaną i akceptowaną we współpracujących grupach a priorytety ich zadań mają na celu realizację tego celu. Promowanie komunikacji, dyskusji, kanału zwrotnego dla decyzji i świętowania sukcesu są kluczowymi strategiami przeciwdziałania temu czynnikowi.
- „malowanie trawy na zielono” – strategia ukrywania dowodów w przypadku zapytania o stan faktyczny, manipulacja dostępnymi danymi na własną korzyść (na poziomie osobistym lub grupy/jednostki organizacyjnej), ponownie ma swoje źródło w braku zarządzania zasobami i przypisania priorytetów do zadań, prowadzi do powstania i utrwalenia błędnego obrazu sytuacji, podejmowaniu wadliwych decyzji i braku świadomości istniejących (ukrytych) podatności jak i znacznego utrudnienia powrotu do stanu normalnego w przypadku braku współpracy przy reakcji na incydent (patrz następny punkt). Konsekwencje tej strategii są bardzo kosztowne, często powodując dużo poważniejsze straty niż tylko bezpośrednie koszty incydentu, prowadzą bowiem do utraty zaufania, zwolnień, wzmocnienia efektu strachu i winy w organizacji, co z kolei zwiększa motywację do pogłębienia tego zjawiska, pozornie wbrew oczekiwaniom. Kompetencje jakie należy wzmocnić to Poznaj, Rozwaga, Reaguj. Strategie organizacyjne przeciwdziałania temu efektowi to promowanie kultury „bez winy”, poszukiwanie prawdziwych źródeł problemów, edukacja, komunikacja i promowanie gier zespołowych wraz z oczywistym promowaniem pracowników i postaw pro-aktywnych w zakresie bezpieczeństwa.
- „to nie ja” – postawa powszechnie spotykana w obliczu konsekwencji wynikających z incydentu bezpieczeństwa. Jest to naturalna reakcja na stres i niespodziewane konsekwencje w ramach próby ich uniknięcia. Efekty tej postawy to mylenie lub podawanie błędnych faktów, zaciemnianie wiedzy, zmiana chronologii wydarzeń – choć zazwyczaj jest to efekt stresu i faktycznego jego wpływu na zdolności postrzegania i zapamiętywania faktów, to po upływie czasu (kilkanaście godzin) staje się już celową strategią ochronną, gdzie fałszowanie obrazu rzeczywistości na własna korzyść staje się celowym zadaniem. W konsekwencji reakcja na incydent i powrót do stanu normalnego znacznie się wydłuża, pojawiają się ślepe wątki, spowalniające i utrudniające faktyczną reakcję na zagrożenie. Głównym powodem późniejszego „braku współpracy” ofiary jest jego przeświadczenie o zeznawaniu przeciwko sobie w związku z obowiązującą w organizacji kulturą winy. Kompetencje jakie należy wzmocnić to Rozwaga (szczególnie z naciskiem na konsekwencje własnych czynów), Reaguj (z naciskiem na możliwość ograniczenia strat przy szybkim raporcie), Odzyskaj (wsparcie dla powrotu do stanu normalnego). Organizacyjnie, krytycznym dla wyeliminowania tego zjawiska jest promowanie „kultury bez winy”, w ramach której z porażek wyciągane są lekcje, których koszt nie ponosi jedynie „operator-ofiara”, wysoce zalecane jest również częste i obejmujące wszystkich pracowników testowanie planów reakcji na incydent wraz ze scenariuszami charakterystycznymi dla każdego pracownika, pozwalające mu zrozumieć odpowiedzialność jaką ponosi na swoim stanowisku pracy.
Przy okazji braku pracy zespołowej nie można nie wspomnieć o kluczowym aspekcie wymiany informacji o zagrożeniach i reakcji na historyczne zdarzenia, oczekiwane od profesjonalistów zajmujących się bezpieczeństwem informacji. Przykładem braku takiej pracy zespołowej i poważnych jej konsekwencji jest incydent w firmie Norsk Hydro, gdzie znany wcześniej malware nie został prawidłowo potraktowany przez dostawców rozwiązań bezpieczeństwa, co uniemożliwiło zablokowanie zagrożenia w momencie jego instalacji. Jak się okazuje, rozwiązaniem mogło być odwołanie znanego certyfikatu, którym podpisany był złośliwy kod, co ułatwiłoby jego zablokowanie albo choćby informacje o anomalnym zachowaniu. Tą unikalną perspektywą problemu Norsk Hydro podzielił się Kevin Beaumont tutaj. Problem wymiany informacji i współpracy organizacji i podmiotów gospodarczych oraz zespołów badaczy czy „obrońców” odpowiedzialnych za reakcję na zagrożenia technologiczne, stanowi podstawę szeregu rekomendacji i dyrektyw, włączając w to: Dyrektywę NIS (a w konsekwencji polską ustawę o krajowym systemie cyberbezpieczeństwa), oraz ostatni Cybersecurity Act dający trwały mandat Europejskiej Agencji Cyberbezpieczeństwa (wcześniej ENISA), wspominając tylko aktywność Uni Europejskiej w zakresie wzmocnienia „pracy zespołowej” w celu zapewnienia bezpieczeństwa w cyberprzestrzeni.
Powyższe przykłady braku pracy zespołowej, czy braku współpracy są jedynie przykładami. Każdy osobiście jest w stanie znaleźć ich więcej w swoim otoczeniu prywatnym i służbowym. Główne pytanie, które pozostawiamy do samodzielnej odpowiedzi to: co z tą wiedzą zrobimy i kiedy?
Spokojnego dnia!
Artur Marek Maciąg
Inicjatywa Kultury Bezpieczeństwa, doświadczony ekspert i pasjonat bezpieczeństwa informacji.